



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题使用GPA2.RAW中的数据。(i)使用所有4137个观测,估计方程并以标准形式报告结论。(ii)使用前20
本题使用GPA2.RAW中的数据。(i)使用所有4137个观测,估计方程并以标准形式报告结论。(ii)使用前20
本题使用GPA2.RAW中的数据。
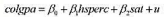
(i)使用所有4137个观测,估计方程
并以标准形式报告结论。
(ii)使用前2070个观测再重新估计第(i)部分中的方程。
(iii)求出第(i)部分与第(ii)部分所得到的标准误的比率。并将这个比率与式(5.10)中的结论相比较。
 答案
答案
查看答案


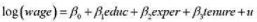
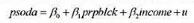

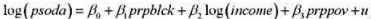
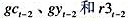 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?


















